
In my last post, “Kleene’s Theorem,” I provided some useful background information about strings, regular languages, regular expressions, and finite automata before introducing the eponymously named theorem that has become one of the cornerstones of artificial intelligence and more specifically, natural language processing (NLP). Kleene’s Theorem tells us that regular expressions and finite state automata are one and the same when it comes to describing regular languages. In the post I will provide a proof of this groundbreaking principle.
Kleene’s Theorem
A language over an alphabet is regular if and only if it can be accepted by a finite automaton.
We can break this theorem down into two separate lemmas that need to proven in order to satisfy the “if and only if” constraint. Remembering that regular expressions are just representations of regular languages, we then need to prove:
Lemma 1
Any regular language can be accepted by a finite state automaton. (There exists a finite state automaton for every regular expression.)
Lemma 2
Any language accepted by a finite state automaton is regular. (There exists a regular expression for any language accepted by a finite state automaton.)
Note that some texts will extend Kleene’s Theorem to include transition graphs stating that in addition to regular expressions and finite state automata being equivalent, that transition graphs are as well. Since transition graphs are just visual representations of FSAs, this seems like a trivial and unnecessary addition IMHO.
As a reminder, the definition of a regular language over an alphabet Σ is:
- The empty language Ø, ie., a set with no strings or the empty string – an empty set, is a regular language.
- The language containing just the empty string, {ε}, is a regular language.
- The singleton sets containing the individual symbols from Σ, {a ∈ Σ}, are regular languages.
- If A and B are regular languages then:
- The union of A and B, A ∪ B, is a regular language.
- A concatenated with B, A • B, is a regular language.
- The Kleene star of A, A*, is a regular language. (The same is true for B.)
- There are no other regular languages over Σ than those described above.
Lemma 1 Proof
Any regular language can be accepted by a finite state automaton. (There exists a finite state automaton for every regular expression.)
We will use the recursive definition of regular languages above to inductively prove this lemma.
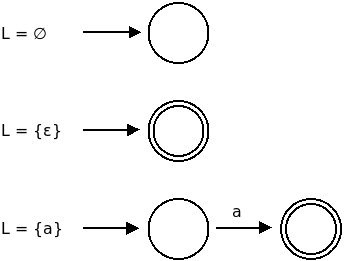
Basis Step
We can construct FSAs for the languages ∅, {ε}, and {a} for any symbol a in alphabet Σ:
Inductive Step
Assume that languages  and
and  are regular languages.
are regular languages.
To complete the inductive proof, we need to show that we can build FSAs for  ,
,  , and
, and  .
.
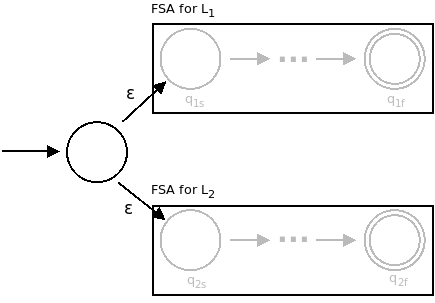
Union
Concatenation

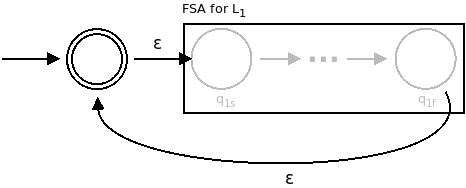
Kleene Star
And that completes the proof. We can create FSAs for the empty language, ∅, the language containing the empty string {ε}, the language consisting of singleton strings, {a}, and for regular languages and , we can build FSAs for , , and . As the definition of regular languages states, there are no other regular languages over Σ than these.
Lemma 2 Proof
Any language accepted by a finite state automaton is regular. (There exists a regular expression for any language accepted by a finite state automaton.)
We can restate this lemma more specifically:
If M = (Σ, S, s0, δ, F) is a finite state automata that recognizes a language R, ie., R = L(M), then there is a regular expression over alphabet Σ that corresponds to R.
Background
By ordering the states using the natural numbers, we can prove this lemma using mathematical induction. Without any loss of generality we can assume that each state in M is an integer from 1 to n where n = |S|.
We define any language that moves M from state p to state q as:

Where:
 the set of strings (language) that moves M from p to q
the set of strings (language) that moves M from p to q
 the Kleene closure over alphabet
the Kleene closure over alphabet 
 the extended transition function,
the extended transition function, 
Any non-deterministic FSA will have just a single path for each string from one state to another. We want to then define what it means to say that a path goes through a specific state.
Consider a string x,  . x can also be thought of as a path through FSA M. If string x moves M from state p to state q,
. x can also be thought of as a path through FSA M. If string x moves M from state p to state q,  , we can say that x goes through state s if:
, we can say that x goes through state s if:
- x = yz (x is the concatenation of strings y and z.)
- |y| > 0 and |z| > 0 (Neither y nor z is the empty string.)
 (String y moves M from p to s)
(String y moves M from p to s) (String z moves M from s to q)
(String z moves M from s to q)
Keeping in mind that we have numbered the states in M from 1 to n where n = |S|, we can a language based on the states it passes through:

“Passing through” does not include starting and stopping states. p may be equal to 8 and q may be equal to 10, but if the intermediate states are 1,3, and 5, then we can say the path goes through no state higher than J = 5.
The set containing just the empty string, {ε}, and all singlet sets, words consisting of single symbols, don’t go through any states.
Finally, since there is no state higher than n,  .
.
For our proof we will use induction to show that for every p where p ≥ 1 and every q where q ≤ n, each set  with 0 ≤ J ≤ n is a regular language.
with 0 ≤ J ≤ n is a regular language.
Basis Step
For all p and q,  is a regular language.
is a regular language.
Explanation
Since we’ve chosen to number the states 1 through n, there is no state 0 and therefore can be no states less than 0. Since we don’t consider the values of states p and q, any path between p and q goes through no other state.
Since there is a single transition between p and q, there two options for :
- is a singlet set. It consists of strings consisting of single symbols from Σ,
 , or
, or - is the set containing only the empty string, = {ε}.
Combining those two possibilities tells us that:

By definition {a ∈ Σ} is a regular language, {ε} is a regular language, and the union of two regular languages is a regular language, so is a regular language.
Inductive Step
Assume that for 0 ≤ k ≤ (n -1) and for every p and q with p ≥ 1 and q ≤ n, then the set  is a regular language.
is a regular language.
To complete the inductive step we need to show that for every p and q with p ≥ 1 and q ≤ n, that the set  is a regular language.
is a regular language.
Consider any string x that is a member of . x represents a path from p to q without going through any state numbered greater than k + 1. There are two exclusive possibilities for x:
- x never goes through state k + 1. For x to be in implies that it is also in . By our assumption, is a regular language, so as a member of the set, x must be regular.
- On the path from state p to state q, x goes through state k + 1 at least once but possibly multiple times.
Since x in case # 1 is regular, we only need to explore the second case. We can rewrite string x as the concatenation of three substrings:

Where:
 is the path from p to k + 1,
is the path from p to k + 1, 
- y is the path from k + 1 the first time it is reached to k + 1 the last time it is passed through,

 is the path from the final instance of k + 1 to q,
is the path from the final instance of k + 1 to q, 
Since we don’t consider the first or last states, we know the highest state that passes through is k. This means that  which implies by our assumption that is regular. By the same reasoning,
which implies by our assumption that is regular. By the same reasoning,  , and by our assumption is regular as well. This leaves string y to be investigated.
, and by our assumption is regular as well. This leaves string y to be investigated.
There are two possibilities for y:
- If x only passes through state k + 1 one time, then y must be the empty string, y = ε.
- x passes through state k+1 multiple but a finite number of times, y ≠ ε.
Considering the second possibility, we can break y down into substrings where each substring represents one loop from state k + 1 back to state k + 1. If y loops r times then:

We will now use the same reasoning that we just used for and . Since for any  , the starting and stopping state is k + 1 , this means that the highest state can pass through is k. Therefore
, the starting and stopping state is k + 1 , this means that the highest state can pass through is k. Therefore  and is regular for all i.
and is regular for all i.
Since y is made up of all the values of concatenated in some order, we can say that  , y is in the Kleene closure of
, y is in the Kleene closure of  . As our definition of regular languages above states, the Kleene star of a regular language, so y must be a regular language.
. As our definition of regular languages above states, the Kleene star of a regular language, so y must be a regular language.
To summarize:
- If x doesn’t go through k + 1 at all then

- If x does go through k + 1 then where


Since x is in , then:

We just finished proving that every language on the right side of the equation is a regular language, and again, the definition of regular language says that they are closed under union, concatenation and Kleene star, so is a regular language, too.
This concludes the proof of Lemma 2. We have shown that:
- For each p, q, and J where 0 ≤ J ≤ n, the set is a regular language.
 – The language that contains all strings from p to q is the same as the language over all states n from p to q because as we’ve seen, any state through which the path of the string does not pass does not contribute to
– The language that contains all strings from p to q is the same as the language over all states n from p to q because as we’ve seen, any state through which the path of the string does not pass does not contribute to  .
.- The language that the FSA accepts, L(M), is a regular language since
 is a regular language.
is a regular language.